Tiered Reasoning for Intuitive Physics: Toward Verifiable Commonsense Language Understanding
Abstract
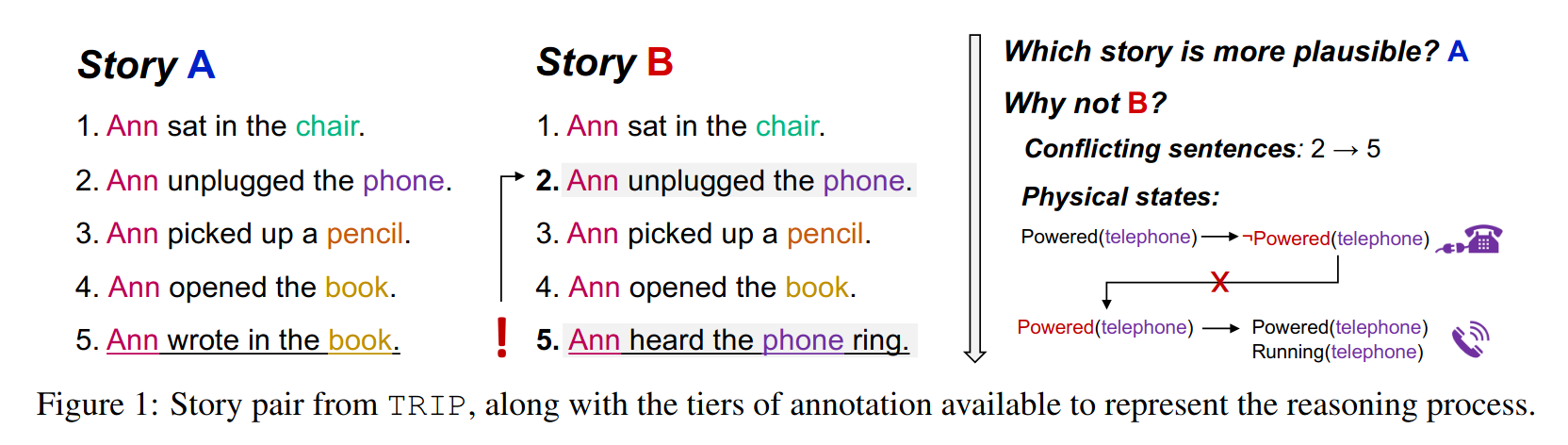
Large-scale, pre-trained language models (LMs) have achieved human-level performance on a breadth of language understanding tasks. However, evaluations only based on end task performance shed little light on machines' true ability in language understanding and reasoning. In this paper, we highlight the importance of evaluating the underlying reasoning process in addition to end performance. Toward this goal, we introduce Tiered Reasoning for Intuitive Physics (TRIP), a novel commonsense reasoning dataset with dense annotations that enable multi-tiered evaluation of machines' reasoning process. Our empirical results show that while large LMs can achieve high end performance, they struggle to support their predictions with valid supporting evidence. The TRIP dataset and our baseline results will motivate verifiable evaluation of commonsense reasoning and facilitate future research toward developing better language understanding and reasoning models.