Hierarchical Task Learning from Language Instructions with Unified Transformers and Self-Monitoring
Abstract
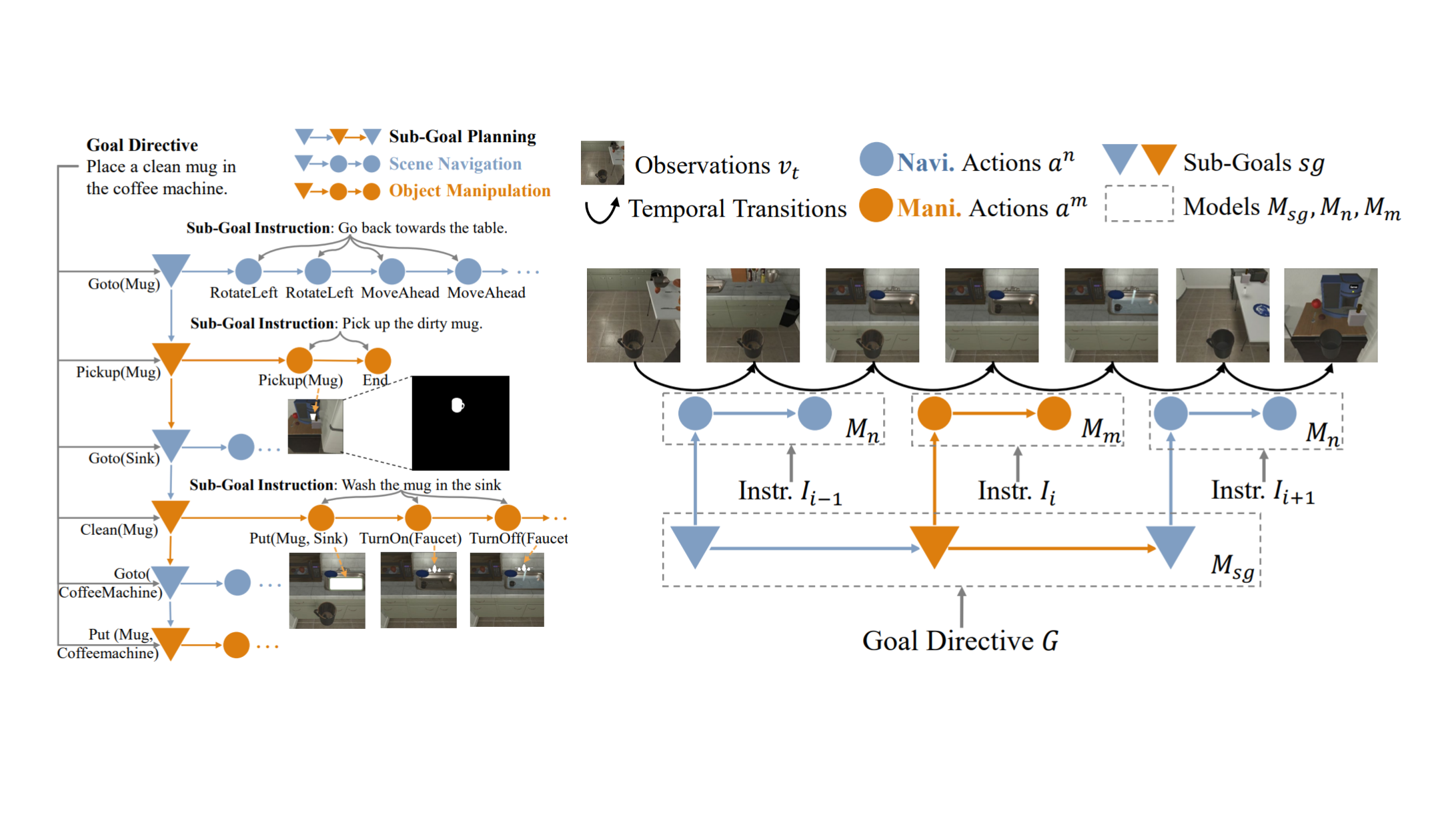
Despite recent progress, learning new tasks through language instructions remains an extremely challenging problem. On the ALFRED benchmark for task learning, the published state-of-the-art system only achieves a task success rate of less than 10% in an unseen environment, compared to the human performance of over 90%. To address this issue, this paper takes a closer look at task learning. In a departure from a widely applied end-to-end architecture, we decomposed task learning into three sub-problems: sub-goal planning, scene navigation, and object manipulation; and developed a model HiTUT (stands for Hierarchical Tasks via Unified Transformers) that addresses each sub-problem in a unified manner to learn a hierarchical task structure. On the ALFRED benchmark, HiTUT has achieved the best performance with a remarkably higher generalization ability. In the unseen environment, HiTUT achieves over 160% performance gain in success rate compared to the previous state of the art. The explicit representation of task structures also enables an in-depth understanding of the nature of the problem and the ability of the agent, which provides insight for future benchmark development and evaluation.