Grounded Semantic Role Labeling
Overview
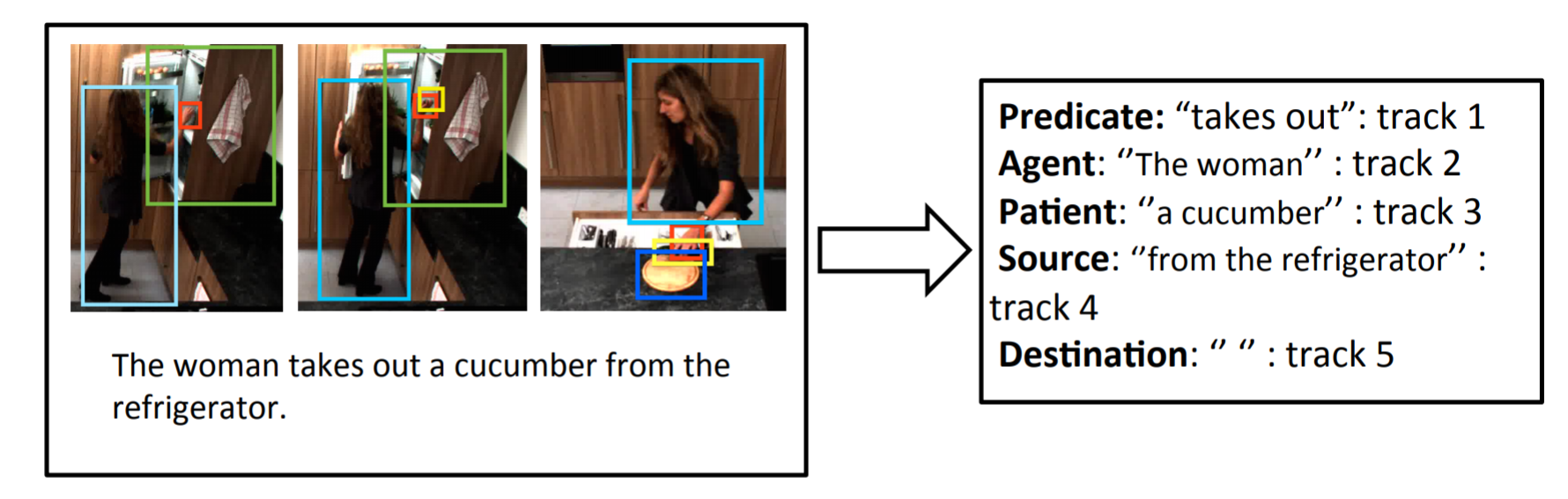
Semantic Role Labeling (SRL) captures semantic roles (or participants) such as agent, patient, and theme associated with verbs from the text. While it provides important intermediate semantic representations for many traditional NLP tasks (such as information extraction and question answering), it does not capture grounded semantics so that an artificial agent can reason, learn, and perform the actions with respect to the physical environment. To address this problem, this paper extends traditional SRL to grounded SRL where arguments of verbs are grounded to participants of actions in the physical world. By integrating language and vision processing through joint inference, our approach not only grounds explicit roles, but also grounds implicit roles that are not explicitly mentioned in language descriptions. This paper describes our empirical results and discusses challenges and future directions.
Datasets
The Dataset contains the video recognition/tracking annotation and text’s semantic role annotation.
Cite Us
Grounded Semantic Role Labeling. Shaohua Yang, Qiaozi Gao, Changsong Liu, Caiming Xiong, Song-Chun Zhu, Joyce Y. Chai. NAACL HLT, 2016. [Paper].
@inproceedings{yang-etal-2016-grounded,
title = "Grounded Semantic Role Labeling",
author = "Yang, Shaohua and
Gao, Qiaozi and
Liu, Changsong and
Xiong, Caiming and
Zhu, Song-Chun and
Chai, Joyce Y.",
booktitle = "Proceedings of the 2016 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2016",
address = "San Diego, California",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/N16-1019",
doi = "10.18653/v1/N16-1019",
pages = "149--159",
}