Commonsense Reasoning and Natural Language Inference
Motivations and Objectives
Motivations
Recent years have seen a surge of research activities toward commonsense reasoning in natural language understanding, i.e., the ability for machines to perform language tasks that require explicit external knowledge or reasoning beyond the context. Dozens of relevant, large-scale benchmark datasets have been developed, and online leaderboards encourage broad participation in solving them. In the last few years, extraordinary performance gains on these benchmarks have come from large-scale language models (LMs) pre-trained on massive amounts of online text, from BERT to GPT-3. Today’s best models can achieve impressive performance and have surpassed human performance in challenging language understanding tasks, even some thought to require commonsense reasoning and explicit knowledge beyond the context. This rapid period of growth and progress has been an undoubtedly exciting time for NLP.
Despite these exciting results, it is a subject of scrutiny whether these models have a deep understanding of the tasks they are applied to. A key concern is widespread bias in language benchmarks allowing systems to bypass reasoning and achieve artificially high performance. Further, existing benchmarks evaluate systems on high-level classification tasks without regard to their underlying process to reach conclusions. Consequently, it remains unclear whether the problems are truly solved, and whether machines have a deep, human-like understanding of the reasoning tasks they can perform to high accuracy.
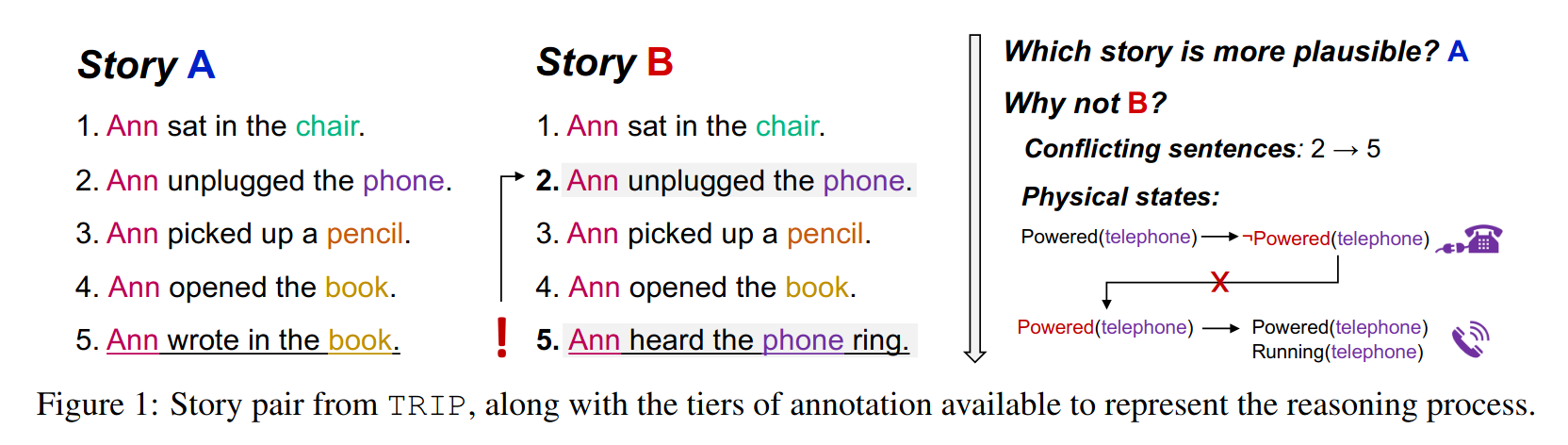
Objectives
Our work targets this question, and our objective is three-fold. First, we aim to expose and evaluate the underlying evidence and inference process used by pre-trained and fine-tuned LMs applied to language understanding problems. Second, we will consider new paradigms and resources for more informative tracking of the state of the art in commonsense reasoning. Lastly, we will investigate the possible methods to improve the suitability of large-scale LMs for reasoning tasks, and enable more coherence, consistency, and verifiability in these state-of-the-art systems.
Related Papers
- Shane Storks, Qiaozi Gao, Yichi Zhang, & Joyce Chai. (2021). Tiered Reasoning for Intuitive Physics: Toward Verifiable Commonsense Language Understanding. Findings of EMNLP 2021.
- Shane Storks & Joyce Chai. (2021). Beyond the Tip of the Iceberg: Assessing Coherence of Text Classifiers. Findings of EMNLP 2021.
- Shane Storks, Qiaozi Gao, & Joyce Chai. (2019). Recent Advances in Natural Language Inference: A Survey of Benchmarks, Resources, and Approaches. arXiv: 1904.01172.