Language Grounding and Alignment in Vision, Robotics and Situated Communication
Motivations and Objectives
Language is learned through sensorimotor and sociolinguistic experiences from the physical world and interactions with humans. The ability to connect language units to their referents (e.g., physical entities, robotic actions) is referred to as grounding and plays an important role in multimodal language processing. For example, concrete action verbs often denote some change of state as a result of an action: “slice a pizza” implies the state of the object pizza will be changed from one piece to several smaller pieces. The change of state can be perceived from the physical world through different sensors. Given a human utterance, if the robot can anticipate the potential change of the state signaled by the verbs, it can then actively sense the environment and better connect language with the perceived physical world such as who performs the action and what objects and locations are involved. This connection will benefit many applications relying on human-robot communication.
Our thoughts and positions:
- Yonatan Bisk, Ari Holtzman, Jesse Thomason, Jacob Andreas, Yoshua Bengio, Joyce Chai, Mirella Lapata, Angeliki Lazaridou, Jonathan May, Aleksandr Nisnevich, Nicolas Pinto, Joseph Turian. Experience Grounds Language. EMNLP, 2020.
Selected Recent Papers
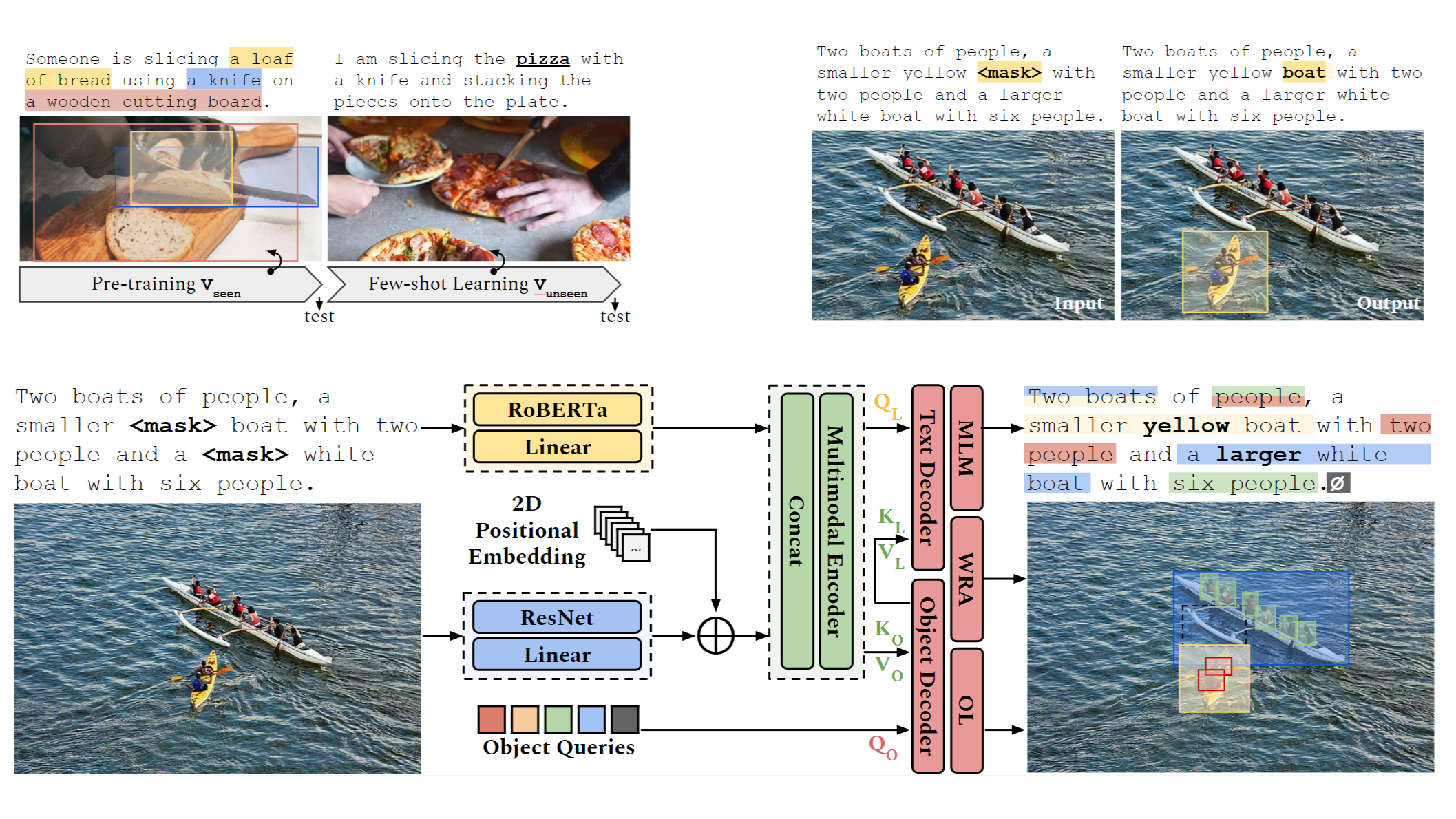
Visual Grounding in Language Acquisition
- Guangyue Xu, Parisa Kordjamshidi, Joyce Chai. MetaReVision: Meta-Learning with Retrieval for Visually Grounded Compositional Concept Acquisition. EMNLP Findings, 2023.
- Ziqiao Ma, Jiayi Pan, Joyce Chai. World-to-Words: Grounded Open Vocabulary Acquisition through Fast Mapping in Vision-Language Models. ACL, 2023. (
Outstanding Paper Award ) - Yuwei Bao, Barrett Lattimer, Joyce Chai. Human Inspired Progressive Alignment and Comparative Learning for Grounded Word Acquisition. ACL, 2023. (
Honorable Mention ) - Lanbo She and Joyce Chai. Interactive Learning of Grounded Verb Semantics towards Human-Robot Communication. ACL, 2017.
- Changsong Liu, Shaohua Yang, Sari Sadiya, Nishan Shukla, Y. He, Song-Chun Zhu, and Joyce Chai. Jointly Learning Grounded Task Structures from Language Instruction and Visual Demonstration. EMNLP, 2016.
- Lanbo She and Joyce Chai. Incremental Acquisition of Verb Hypothesis Space towards Physical World Interaction. ACL, 2016.
Referential Grounding in Situated Communication
- Rui Fang, Malcolm Doering, Joyce Chai. Embodied Collaborative Referring Expression Generation in Situated Human-Robot Dialogue. HRI, 2015.
- Rui Fang, Malcome Doering, Joyce Chai. Collaborative Models for Referring Expression Generation towards Situated Dialogue. AAAI, 2014.
- Changsong Liu, Lanbo She, Rui Fang, Joyce Chai. Probabilistic Labeling for Efficient Referential Grounding based on Collaborative Discourse. ACL, 2014.
- Rui Fang, Changsong Liu, Lanbo She, Joyce Chai. Towards Situated Dialogue: Revisiting Referring Expression Generation. EMNLP, 2013.